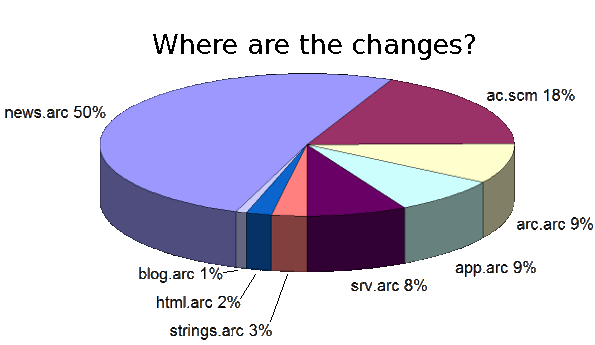news.arc, the Arc source code for the Hacker News forum. Examining this code can give some insight into the ranking algorithm that selects the top articles on the Hacker News forum.
The ranking formula
In outline, each item is given a ranking, and the articles are sorted according to the ranking. The simplistic way to think about ranking is the number of votes is divided by time, so more votes results in a higher ranking, but the ranking also drops over time. The votes are raised to a power less than one, while the time is raised to a power greater than one, so time has more effect than votes. Some additional penalties also may be applied to the ranking.
To be specific, the following is the ranking code from news.arc:
(= gravity* 1.8 timebase* 120 front-threshold* 1
nourl-factor* .4 lightweight-factor* .3 )
(def frontpage-rank (s (o scorefn realscore) (o gravity gravity*))
(* (/ (let base (- (scorefn s) 1)
(if (> base 0) (expt base .8) base))
(expt (/ (+ (item-age s) timebase*) 60) gravity))
(if (no (in s!type 'story 'poll)) 1
(blank s!url) nourl-factor*
(lightweight s) (min lightweight-factor*
(contro-factor s))
(contro-factor s))))
This algorithm can be expressed as a (slightly simplified) equation:
![]()
This ranking algorithm is used for items on the front page as well as for ordering the comments on an item.
The key factor in the ranking formula is the exponent on time (i.e. the optional parameter gravity) is higher than the exponent on the votes. As a result, even if an item keeps getting a large number of votes, eventually the denominator will overwhelm it and its ranking will drop. For example, if a popular item gets 100 votes an hour, eventually it won't be able to keep pace with a new item getting 10 votes an hour. This ensures that even the most popular items won't stay on the list forever. In other words, gravity controls how fast articles get pulled down in ranking.
By default, the scoring function scorefn is the realscore, which is the net votes for an item ignoring any upvotes from pontential sockpuppet accounts. Sockpuppet accounts are accounts created to manipulate voting, and an account is considered potentially a sockpuppet based on several simple factors.
Because the score is given an exponent of .8 (for positive scores), the benefit of large numbers of votes is reduced. Mathematically, though, this exponent could be eliminated. Since only relative rankings matter, raise everything to the 1/.8 power, and the numerator's exponent disappears, along with the need for the negative check. This would be a win from the "code golf" perspective.
A few other constants are of interest. Since 1 is subtracted from the score, an item starts off with a rank of 0. In the denominator, 120 minutes are added to the time. Thus, an article can be considered two hours old at time of posting, limiting the ranking boost for very recent articles. The front-threshold* specifies a minimum ranking score for articles to appear.
Penalties
A story (i.e. a normal posting) or poll can receive additional ranking penalties. The penalties are not applied to comments or poll options. The penalties are as follows:- An item with a blank url is penalized by
nourl-factor*. This lowers the ranking of an "Ask HN" item, for instance. - A "lightweight" item is penalized.
- A "controversial" item is penalized.
lightweight-factor*. (The code doesn't show how a "rallying cry" is determined.)
The contro-factor penalty is applied to controversial articles. The contro-factor is computed as:
(def contro-factor (s)
(aif (check (visible-family nil s) [> _ 20])
(min 1 (expt (/ (realscore s) it) 2))
1))
An item with too many comments (at least 20 and more comments than upvotes) gets the contro-factor penalty. An item's visible-family is the number of visible comments (plus one for the item itself). If the visible-family is more than 20, the penalty is:
![min\left[ 1, \left( \frac{realscore}{visible\-family}\right) ^{2} \right]](http://static.righto.com/images/contro.gif)
A lightweight item gets the worse of the "lightweight" and "contro-factor" penalties. The contro-factor penalty is only applied if less than 1; i.e. an item can't get a boost from it. Because the ratio is squared, the effect of the penalty is more substantial. I would have expected contro-factor to penalize controversial comment subthreads too, but apparently it doesn't.
How the ranking is performed
When the server starts up, it loads the top stories from atopstories file. If the file is not present, it uses the ranking algorithm to select the top 180 stories out of the most recent 1000 stories. Stories normally are re-ranked by adjust-rank only when they receive a vote. Interestingly, only the updated item is re-ranked, rather than doing a global re-rank, probably for efficiency reasons. The adjust-rank function also saves the top 180 items to thetopstories file to disk.
There's also a background reranking thread to rerank a random story from the top 50 every 30 seconds (again using adjust-rank). This ensures that stories that are no longer receiving any votes at all get reranked occasionally.
As far as I can tell, the list of ranked stories never gets shrunk (except on restarts), but the number of displayed stories is capped at 210; you will hit this limit if you keep paging through the top stories.
Comparison with Arc2
The old code in arc2 is much simpler:
(= gravity* 1.4 timebase* 120 front-threshold* 1)
(def frontpage-rank (s (o gravity gravity*))
(/ (- (realscore s) 1)
(expt (/ (+ (item-age s) timebase*) 60) gravity)))
The main differences are that arc3 has higher gravity, so articles will drop off faster; arc3 has an exponent on the numerator, and arc3 adds the various penalties. This illustrates that the ranking formula is changing and gaining complexity over time.
Conclusions
There may be differences there are between the live Hacker News server andnews.arc, so my analysis may not exactly describe what's really happening. I'd assume the code is constantly being modified; comparison with arc2 shows that the ranking formula has become considerably more complex. In addition, news.arc has some YC-specific stuff removed.. Finally, since this is Arc, the ranking constants and even the algorithms can be changed at the REPL while the server is running. Thus, the live ranking algorithm might never actually exist in a source file.
So, what's the secret to getting a high-ranked article? I don't see any magic bullets in the code, just the obvious: get lots of upvotes in a short period of time, avoid penalties (don't post fluff), and don't use sockpuppets.
 .
.