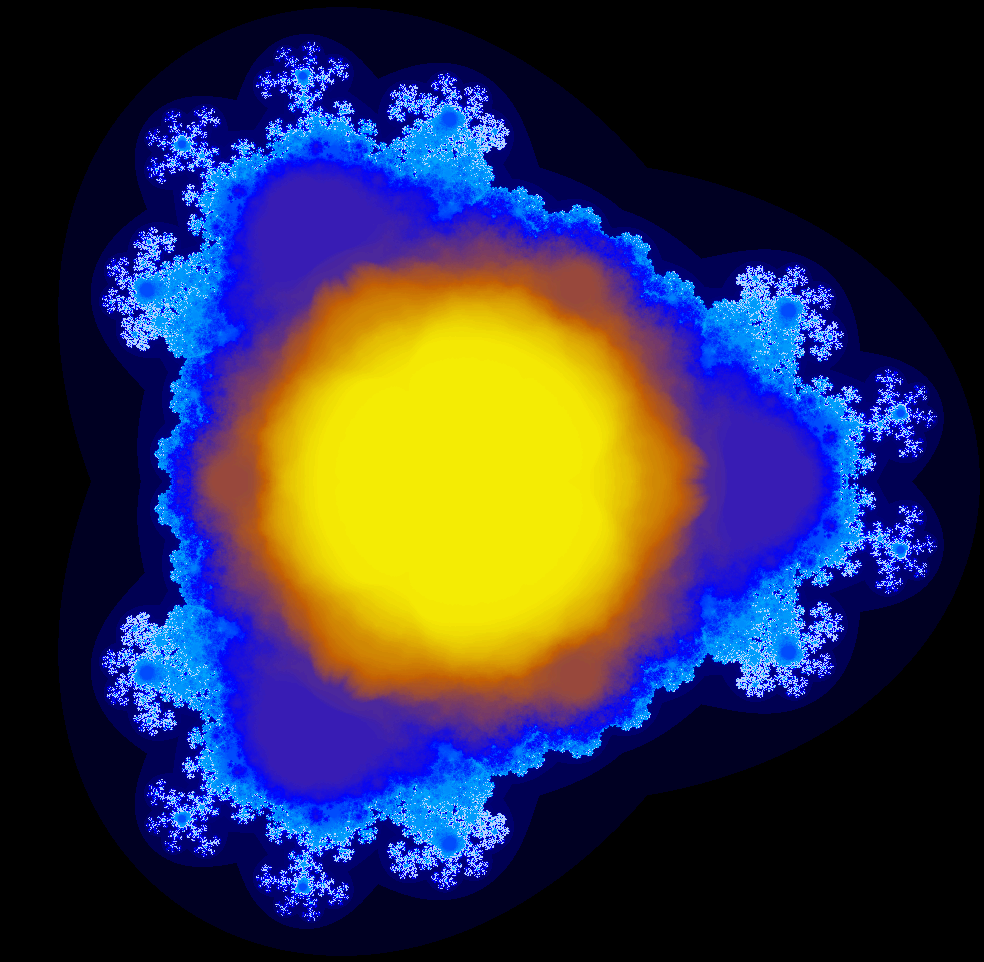
The Mandelbrot fractal is generated by repeatedly iterating the complex function f(z) = z^2 + c, and testing if the result diverges to infinity or not. An obvious generalization is to use a different exponent in place of 2 (yielding a fractal sometimes called the Multibrot). In this article, I describe a new algorithm for fractals with a rational exponent, for example z^2.5+c. This algorithm uses all branches of the complex roots in parallel, rather than just the principal root, which displays new structure of the fractal.
Previous techniques to display fractional-exponent fractals force the multi-valued complex root to have a single value, which distorts the "true" fractal. By computing all the possible root values in parallel, I determine the "true" form of the fractal.
The following image shows the multi-branch fractal for z^2.5+c. Click on the image (or any of the other images) for a full-size version.
The problem with square roots
Numbers generally have two square roots, although we typically only think about the principal (positive) one. For instance (-2)2 = 22 = 4, so sqrt(4) = +2 or -2. (Zero is the exception.) Likewise, complex numbers have two square roots. Unfortunately, we can't just pick one of the square roots without running into discontinuities. For instance, suppose we start with sqrt(1) = 1. Then look at sqrt(i), sqrt(-1), and sqrt(-i) on the following diagram. The roots are nice and continuous from (A) to (D) until we end up back at (E), where sqrt(1) = -1. Something has to give; somewhere the square root function is going to become discontinuous.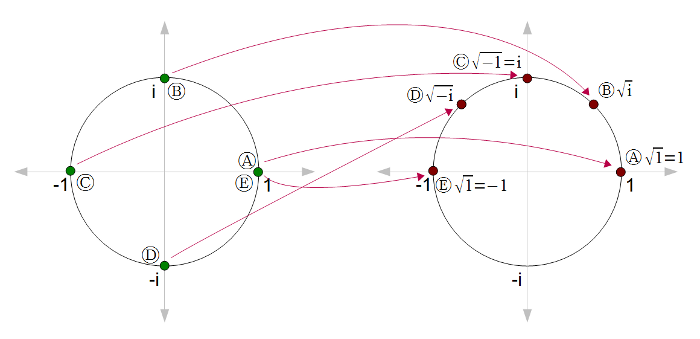
This problem can be solved by making a branch cut, where the function is discontinuous. This cut is typically along the negative real axis, so at point (C) the square root function would jump from i to -i. Note that cutting along the negative real axis is arbitrary.
The disadvantage of making the square root function discontinuous is the resulting fractatals will have discontinuities. In addition, the appearance of the fractal will change if the arbitrary cut is made in a different location. Thus, in a sense, if you generate a fractal based on z^2.5+c, you're not seeing the real fractal, but artifacts based on arbitrary decisions.
Multi-valued complex functions can be expressed as Riemann surfaces. Instead of being defined on the complex plane, the function is defined on a surface which locally looks like the complex plane, but can have more structure. For instance, the following illustration shows the Riemann surface for the complex square root. Note that for each point (except 0), there are two values for the square root.
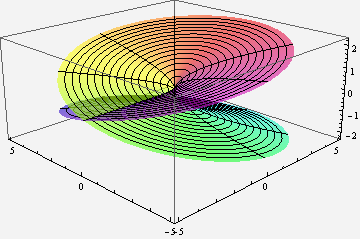
ParametricPlot3D[{r * Cos[theta], r * Sin[theta], Sqrt[r] * Cos[theta/2]}, {theta, 0, 4Pi}, {r, 0, 5}, PlotPoints -> 100, PlotStyle->Opacity[.6], ViewPoint -> {-2, -2, 1}, Mesh->True, ColorFunctionScaling->False, ColorFunction -> Function[ {x,y,z,theta, r}, Hue[theta/(4Pi), .9, .9]]]
How do you compute a complex root?
In general, a complex power a^b is defined as exp(b * ln(a)), using the complex exponential and logarithm. The complex logarithm is multi-valued, which is the base of the multi-valued problems. These functions can be computed using well-known formulas.Because I'm using square roots instead of arbitrary powers (for now), I can use a simpler complex square root formula (details at Wikipedia). The following code takes a complex number x + i * y, and returns the primary square root x1 + i * y1. Note that the negative -(x1 + i * y1) is the other square root.
public static void csqrt(double x, double y, ref double x1, ref double y1)
{
double m = x * x + y * y;
double r = Math.Sqrt(m);
x1 = Math.Sqrt((r + x) / 2.0);
if (y > 0) {
y1 = Math.Sqrt((r - x) / 2.0);
} else {
y1 = -Math.Sqrt((r - x) / 2.0);
}
}
Generating the real fractal, with all the branches
The key idea of the multi-branch algorithm is instead of forcing the square root function to have a single arbitrary value, embrace the multi-valued nature of the square root and try both values. In this way, we can see the "true" picture of the fractional-exponent Mandelbrot set. Specifically, instead of taking one value for the square root, the algorithm evaluates the fractal recursively trying each square root in turn. The two return values are combined to yield the final result.To generate the multi-branch fractal, we can test each point to see if any branch converges. However, the result is more interesting if we count how many of the branches converge for each pixel. The result can be anywhere between all of them (in the middle of the fractal) to none of them (outside the fractal).
To decide if a point diverges, I use the standard escape-time technique of checking if the magnitude of z exceeds a bound. If z exceeds the bound, I know the point diverges. If z doesn't exceed the bound by the end of the iterations, I assume it doesn't diverge. This is not necessarily true, which is why the accuracy of a fractal increases as the number of iterations increases. I test for divergence with a bound of magnitude^2 > 4; the exact value of the bound doesn't make much difference as long as it is large enough to guarantee divergence.
The following code shows how the number of convergent branches c is computed recursively. Note that (z25x, z25y) is one of the values of z^2.5, and (-z25x, -z25y) is the other. The key to the multi-branch fractal is that both paths are explored, rather than just one. For a particular pixel, eval(x, y, x, y, 0) is called and the the result is displayed with a suitable colormap.
int eval(double zx, double zy, double cx, double cy, int n)
{
if (n == max)
{
return 1;
}
// zsquared is z^2, zroot is sqrt(z), z25 is z^2.5
double zsquaredx = zx * zx - zy * zy;
double zsquaredy = 2 * zx * zy;
double zrootx = 0, zrooty = 0;
CMath.csqrt(zx, zy, ref zrootx, ref zrooty);
double z25x = zsquaredx * zrootx - zsquaredy * zrooty;
double z25y = zsquaredx * zrooty + zsquaredy * zrootx;
int c = 0;
// Use the first root
double newx1 = z25x + cx;
double newy1 = z25y + cy;
if (newx1 * newx1 + newy1 * newy1 < 4)
{
c += eval(newx1, newy1, cx, cy, n + 1);
}
// Use the second root
double newx2 = -z25x + cx;
double newy2 = -z25y + cy;
if (newx2 * newx2 + newy2 * newy2 < 4)
{
c += eval(newx2, newy2, cx, cy, n + 1);
}
return c;
}
The multi-branch fractal is exponentially slow compared to regular escape time fractals. At each iteration, there are two choices of square root, with the consequence that we evaluate 2^n values at each pixel, rather than n with a normal escape-time fractal. Unfortunately, this makes computation very expensive. For a regular escape-time fractal, you might use an iteration depth of hundreds for each pixel. But for the multi-branch fractal, it gets very slow if you go above about 12 iterations.
The above algorithm provides detail of the "inside" of the multi-branch fractal. Note that there is a central region where every branch converges. This isn't too surprising, since if c is sufficiently small, z^2.5 will converge with either branch. Outside this region is a complex area where points just barely converge on some branches, and flipping the branch anywhere will make the point diverge. The eight "snowflake" buds are what I find most interesting; these are regions that diverge for almost all branches, but converge for the "right" branches.
The resulting fractal is obviously symmetric when reflected in the y axis or when rotated by 60 degrees. The proofs are straightforward . In comparison, the regular z^2.5+c fractal is not rotationally symmetric because of the effect of branch cuts.
I believe the multi-branch fractal is connected (unlike the regular z^2.5+c fractal), but I don't have a proof. Interestingly, the fractal has some holes (i.e. is not simply connected). I believe these happen where different branches overlap in such a way that they happen to leave gaps, but on a particular branch (whatever that means) the fractal does not have holes.
The best way to see the holes is to look at the "outside" of the fractal. Instead of counting how many branches converge, the code can be easily modified to determine the maximum number of iterations it takes for a branch to diverge. This is similar to the standard escape-time fractal algorithm with level sets approaching the fractal (except of course, it uses multiple branches). In the image below, you can see dark blue spots inside the fractal near the "snowflakes" that look like image noise. These are actually areas that are outside the fractal with complex structure.

Stepping through iteration-by-iteration
One way to understand the multi-branch fractal is to step through one iteration at a time. If we start with one iteration, there are two branches at each pixel. We see a central region that converges for both branches, and three lobes that converge only for one branch. Note that the boundary wraps around the center twice. Perhaps you can imagine this boundary on the Riemann surface at the top of the page.




Snowflakes and the Monkey's Paw
The "snowflakes" are made of a repeated motif that I call the "monkey's paw". Looking at one of these regions while increaing the number of iterations helps illustrate some of the structure of the fractal. After 3 iterations, a basic four-fingered "paw" is visible.


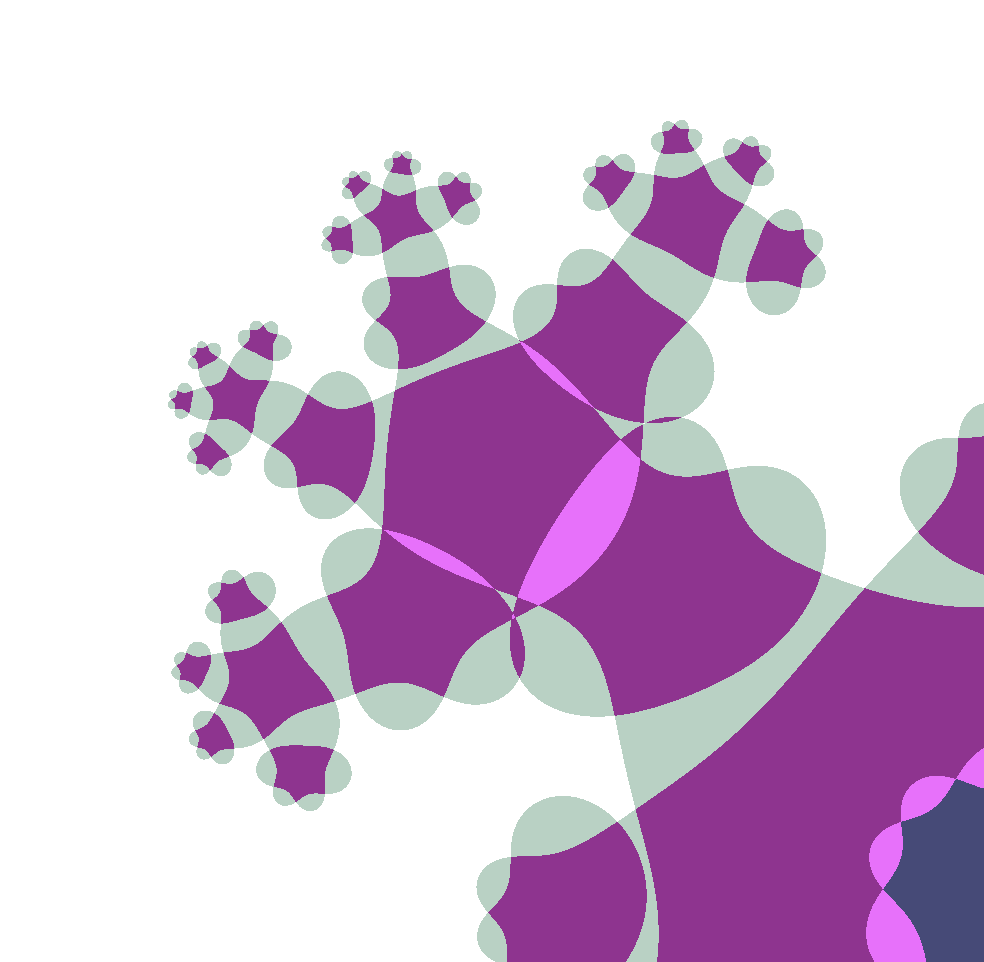


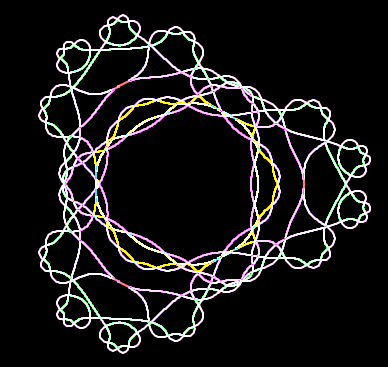
Edge detection
Another way to see the structure is to filter the fractal to show the edges. This shows the structure of the boundary between convergent and divergent regions. The following image show the boundary after three iterations. If you follow the line around, you can see its complex structure.

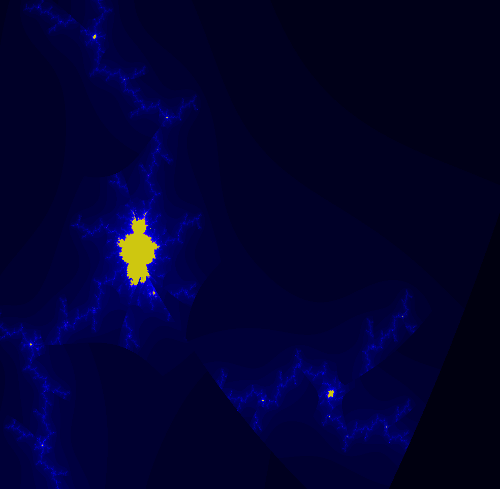
Comparison with the "regular" escape-time fractal
Comparing the multi-branch fractal with the single-branch fractal shows some interesting features. The image below is the fractal generated from z^2.5+c using the standard algorithm. Superficially, it looks a lot like the Mandelbrot set. However, note that it is not connected, with some unconnected islands in the upper center for example.
Below is the same region of the fractal, displayed using the multi-branch algorithm. Note that there is much more detail provided by the multi-branch algorithm. Also note that the stable self-similar region looks very much like the overall multi-branch fractcal.

The regular fractal is actually a subset of the multi-branch fractal, since each computation in the single-branch fractal will be done in one of the paths of the multi-branch fractal. In the image below, the regular fractal has been overlayed on the multi-branch fractal. Note that the regular fractal exactly falls onto the multi-branch fractal, but is missing most of the branchess. Clicking on the image below will show an animation flipping between the regular fractal and the multi-branch fractal.
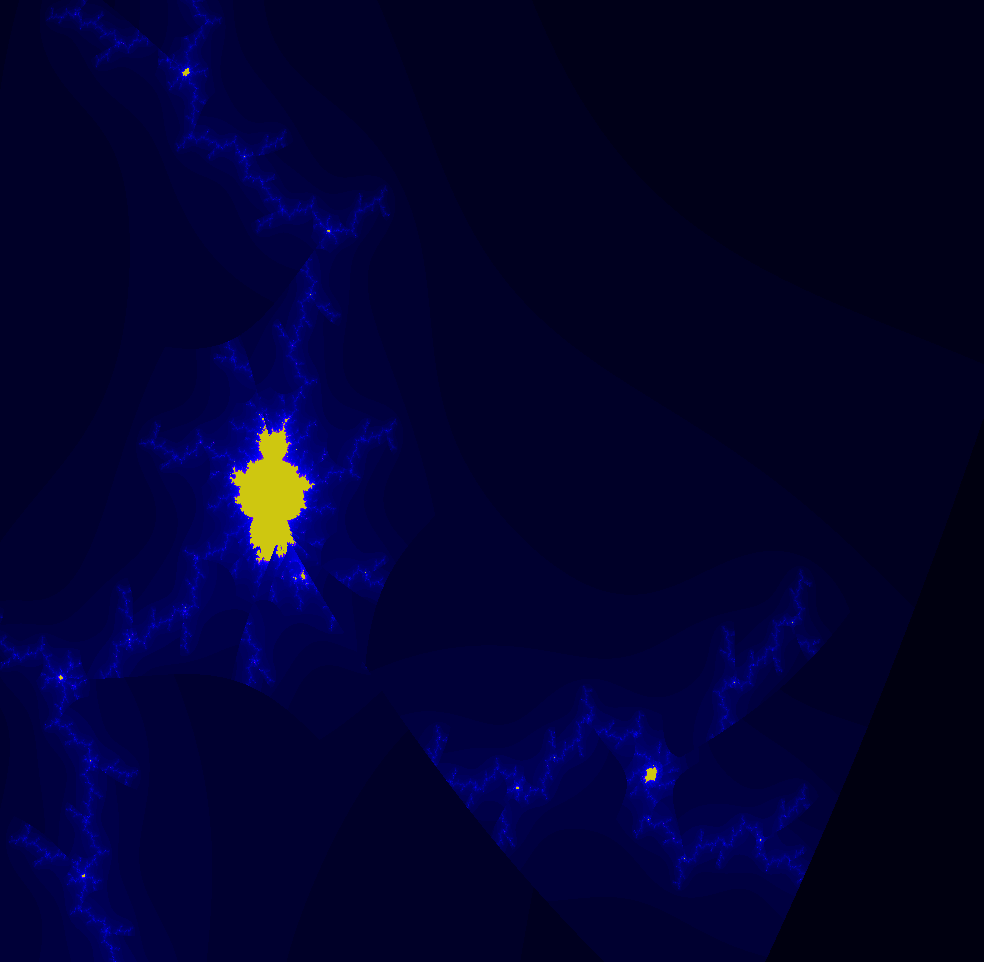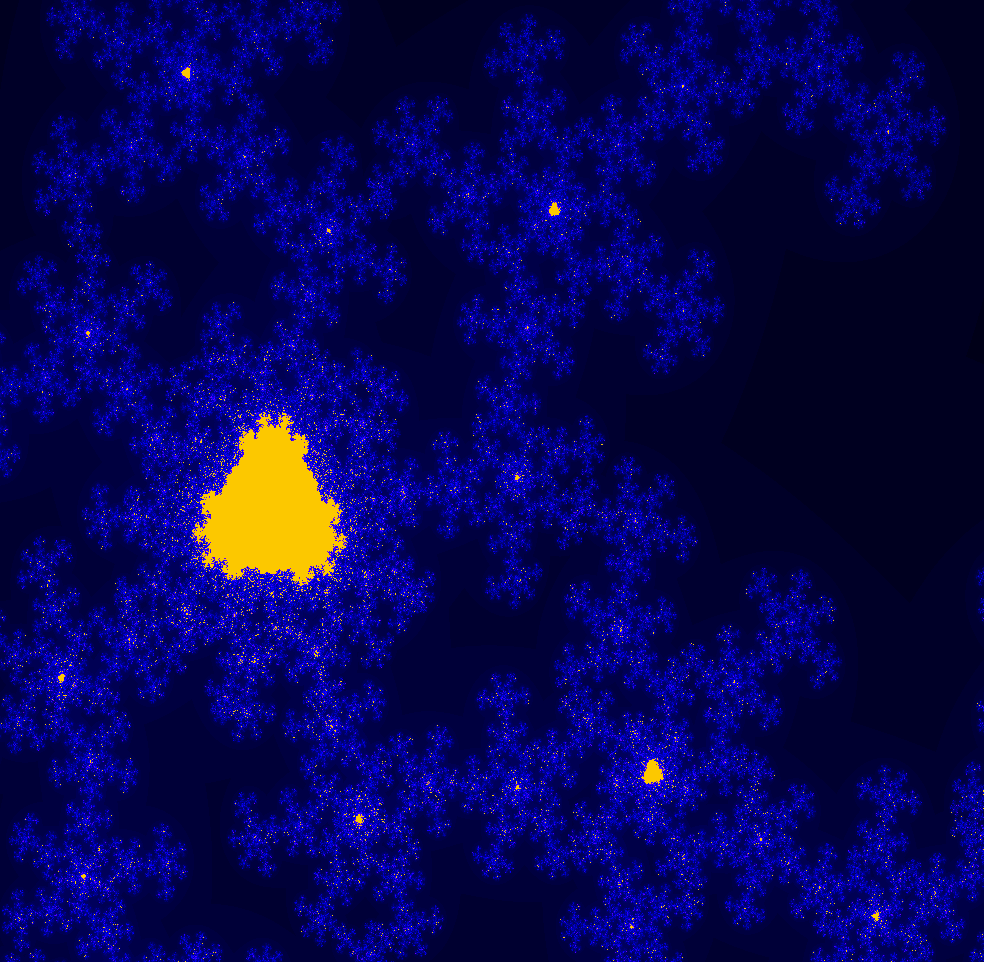
One surprising thing is how different the regular and multi-branch fractals look in general. The regular fractal looks much more "Mandelbrot-like" with its sequences of bulbs. I expect that the multi-branch fractal also has a similar structure, but hidden by the overlapping branches.
Another way of seeing how the fractals are related is to overlay the regular fractal with the edge map of the multi-branch fractal. In the following image, both fractals are rendered to a depth of 5 iterations. The regular fractal is displayed in cyan on top of the edges of the multi-branch fractal. Note that the edges match exactly, which is expected from the mathematics. Note also that the regular fractal jumps from curve to curve as it hits the branch cuts, rather than following a single curve. Also note how much of the multi-branch struture is missed by the regular fractal. (The regular fractal is very "blobby" because the iteration count is so low. A higher iteration could would make it too hard to see the edges.)

What's next?
There are many more things to explore with multi-branch fractals. The techniques can easily be extended to values other than 2.5. Rendering Julia sets instead of Mandelbrot sets is straightforward, but I haven't looked into that yet; it's just a matter of fixing c and varying z, instead of varying z.A more interesting exploration is looking at the fractal in three dimensions. In particular, I want to examine the Riemann surface structure in more detail. I think separating out the sheets of the surface will expose much more of the fractal structure, which gets hidden when all the sheets are projected together. I tried to compute the Riemann surface for just two iterations of a similar function using Mathematica but the result is almost incomprehensible:

RiemannSurfacePlot3D[ w == (z^2.5+z)^.5, Re[w], {z, w}, PlotPoints -> {46, 44}, ImageSize -> 1260, Coloring -> Hue[Im[w]/8]]/. gc_GraphicsComplex :> {Opacity[0.66], gc} Multi-sheet z^2.5+c fractal at (-.90, 1.14): 5 iterations, edges of escape regions
I think the orbit behavior of individual starting points is a key to understanding this fractal. For instance, which starting points yield a 1-cycle, 2-cycle, and so forth. It's hard to define these cycles exactly, because of the multi-value nature of the fractal. A value can converge to a fixed point on one branch, but not another.
Another mathematical feature that I think is key to understanding the fractal is points where the value goes to zero. The function has many more zeros than I expected, and they are concentrated at "interesting" points of the fractal. The zeros are where the Riemann surfaces come together, and also the points where the boundary forms "loops".
I've been exploring different ways of displaying cycles and zeros, and hope to post images soon, but this post is already very long, so I'll leave those for Part II.
Related work
Many people have generated Mandelbrots with non-integer exponents, but always using a single-valued function. Wikipedia has a summary under the title Multibrot set.I started investigating multi-branch fractional exponents many years ago but computers weren't powerful enough at the time, so my investigation didn't get very far. My negative integer exponents were easier to compute and I wrote a paper about those fractals: ``An Investigation of z -> 1/z^n+c,'' Computers & Graphics, 17(5), Sep. 1993, pp 603-607.
Joshua Sasmor has done an extensive investigation of non-integer exponents in his PhD thesis "Fatou, Julia and Mandelbrot Sets for Functions with Non-Integer Exponent" and in the paper "Fractals for functions with rational exponent", Computers and Graphics 28(4). Also of interest is his presentation Julia Set and Branch Cuts which shows the Julia set for z^2.5 - 1/2 + i/10 using inverse iteration instead of escape time. I suspect that his inverse iteration Julia set algorithm yields results similar to applying my multi-branch algorithm to Julia sets. I haven't explored this yet, but if true, it would provide more evidence that the multi-branch algorithm gives the "real" structure of the fratals.
There are several interesting videos that show the evolution of the generalized Mandelbrot set as the exponent changes. A few examples are Mandelbrot Set from 1 to 100 with zoom, Cut along negative X axis, and Cut along negative Y axis. It is interesting to compare the last two, to see how different the results are if the branch cut is placed in a different location.