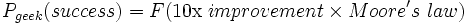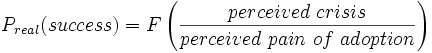I came across a thread on reddit about
why you shouldn't write your own encryption algorithm. In it, one person presented a
homegrown algorithm with a
challenge to break it. The algorithm turned out to be the weak
Vigenère cipher, so I thought it would be interesting to break it with Arc.
In a Caesar cipher, each character in the plaintext is shifted by a fixed amount. For instance, if the shift is 3, "a" becomes "d", "b" becomes "e", and so on. In the Vigenère cipher, multiple shifts are used. For instance, if the key is (2, 4, 9), the first character is shifted by 2, the second character is shifted by 4, the third character is shifted by 9. The pattern then repeats with shifts of 2, 4, 9, 2, 4, 9, and so on until the entire plaintext is encrypted. Note that the length of the key is arbitrary.
The encrypted string of the reddit cipher can be expressed in Arc as:
(= s "t/GlC/,@RiG.^(xBQ2.MslF27@w#xXw,KHx,/9xiU-(!\"ixf%\";iA-=@wiW-=6EnRX#,stL-\"6Mqy!6:HDf#,6LDA0,)LoS9@:slPY9!xmx!?/LiM,,MsjL16@xCx.,6zrT26:HDx-$,svM/,6MnQ!P6sXz#/%NBJ^6jsly,6#ttCX/+sjx9/+MuCX8/MiFY(.xAx$/+AxS!69AjL4/$ziR5,6tuE-(/MqKC")
The first thing we can do is determine how long the key is. Since the key repeats, it is likely that characters in the ciphertext will also repeat with the same frequency. We can apply a simple autocorrelation function:
(def autocorrelate (s offset)
(let total 0
(for i 0 (- (len s) offset 1)
(if (is (s i) (s (+ i offset)))
(++ total)))
total))
This function will compare each character with the character
offset later in the string, and count the number of matches. Let's find the best value for
offset:
(for i 1 20 (prn i " " (autocorrelate s i)))
1 2
2 3
3 1
4 6
5 6
6 16
7 6
8 3
9 0
10 1
11 3
12 16
13 7
14 5
15 0
16 3
17 5
18 17
19 1
20 3
Note that comparing each character with the character 6 characters later has 16 matches, which is much better than the other offsets. So it's pretty likely that the key is length 6. (There are also spikes at multiples of 6, as you'd expect.)
Now let's make a function to decode an encrypted character given an offset. We need the algorithm's character set mapping m used to shift the characters. The typical Vigenère uses a character set of 26 letters, but the challenge algorithm uses a much larger character set. To decode a character, we look it up in the mapping to get an integer index, shift by the offset, and convert back to a character.
(= m " abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.,-\'?/\\!@#$%^*()+=~\";:")
(def decodechar (ch offset)
(m (mod (- (pos ch m) offset) (- (len m) 1))))
For example, if our characters were shifted by 3, "D" should decode as "A":
(decodechar #\D 3)
#\A
At this point, there are multiple approaches to break the cipher. If you have any known plaintext, you can immediately get the key. Without a known plaintext, you can take an expected plaintext such as " the " and drag it through the ciphertext, generating a presumtive key at each point. If the same pattern pops out in several places, you may have the key.
Alternatively, if we take every 6th character in the ciphertext, we have 6 Caesar cipers, and we can break each one separately. Breaking a Caesar cipher is easy. One approach is frequency analysis; assuming there are more e's and t's than q's and z's in the plaintext, you can compute the likelihood of each key. Log-likelihood is a typical way, but Arc doesn't have a log function, annoyingly enough.
I decided to take a more brute force approach. I made a function that prints out the decoding of one of the Caesar substrings given an offset value.
(def decodesubstring (s startpos skip offset)
(loop (= i startpos) (< i (len s)) (= i (+ i skip))
(pr (decodechar (s i) offset)))
(prn))
For instance, to take every sixth character, starting with the second, and shift it by 35:
(decodesubstring s 2 6 35)
"i$/#b$UV#=/d;cc/$c/$^;/d/e/\/dd$**^\d
That deciphering doesn't look too good if we're looking for English text. Either our plaintext is a Perl program or 35 is the wrong offset. Let's brute-force try all the offsets:
(def testall (s startpos skip)
(for i 0 (len m)
(pr i " ")
(decodesubstring s startpos skip i)))
(testall s 2 6)
0 GRxswKx";wEsMHLLsxLsxzHsMsNstsMMxAAztM
1 FQwrvJw~"vDrLGKKrwKrwyGrLrMrsrLLwzzysL
2 EPvquIv=~uCqKFJJqvJqvxFqKqLqrqKKvyyxrK
3 DOuptHu+=tBpJEIIpuIpuwEpJpKpqpJJuxxwqJ
4 CNtosGt)+sAoIDHHotHotvDoIoJopoIItwwvpI
5 BMsnrFs()rznHCGGnsGnsuCnHnInonHHsvvuoH
6 ALrmqEr*(qymGBFFmrFmrtBmGmHmnmGGruutnG
7 zKqlpDq^*pxlFAEElqElqsAlFlGlmlFFqttsmF
8 yJpkoCp%^owkEzDDkpDkprzkEkFklkEEpssrlE
9 xIojnBo$%nvjDyCCjoCjoqyjDjEjkjDDorrqkD
10 wHnimAn#$muiCxBBinBinpxiCiDijiCCnqqpjC
11 vGmhlzm@#lthBwAAhmAhmowhBhChihBBmppoiB
12 uFlgkyl!@ksgAvzzglzglnvgAgBghgAAloonhA
13 tEkfjxk\!jrfzuyyfkyfkmufzfAfgfzzknnmgz
14 sDjeiwj/\iqeytxxejxejlteyezefeyyjmmlfy
15 rCidhvi?/hpdxswwdiwdiksdxdydedxxillkex
16 qBhcguh'?gocwrvvchvchjrcwcxcdcwwhkkjdw
17 pAgbftg-'fnbvquubgubgiqbvbwbcbvvgjjicv
18 ozfaesf,-emaupttaftafhpauavabauufiihbu
19 nye dre.,dl toss es ego t u a ttehhgat
20 mxd;cqd9.ck;snrr;dr;dfn;s;t; ;ssdggf s
21 lwc"bpc89bj"rmqq"cq"cem"r"s";"rrcffe;r
22 kvb~aob78ai~qlpp~bp~bdl~q~r~"~qqbeed"q
23 jua= na67 h=pkoo=ao=ack=p=q=~=ppaddc~p
24 it +;m 56;g+ojnn+ n+ bj+o+p+=+oo ccb=o
25 hs;)"l;45"f)nimm);m);ai)n)o)+)nn;bba+n
26 gr"(~k"34~e(mhll("l(" h(m(n()(mm"aa )m
27 fq~*=j~23=d*lgkk*~k*~;g*l*m*(*ll~ ;(l
28 ep=^+i=12+c^kfjj^=j^="f^k^l^*^kk=;;"*k
29 do+%)h+01)b%jeii%+i%+~e%j%k%^%jj+""~^j
30 cn)$(g)Z0(a$idhh$)h$)=d$i$j$%$ii)~~=%i
31 bm(#*f(YZ* #hcgg#(g#(+c#h#i#$#hh(==+$h
32 al*@^e*XY^;@gbff@*f@*)b@g@h@#@gg*++)#g
33 k^!%d^WX%"!faee!^e!^(a!f!g!@!ff^))(@f
34 ;j%\$c%VW$~\e dd\%d\%* \e\f\!\ee%((*!e
35 "i$/#b$UV#=/d;cc/$c/$^;/d/e/\/dd$**^\d
36 ~h#?@a#TU@+?c"bb?#b?#%"?c?d?/?cc#^^%/c
37 =g@'! @ST!)'b~aa'@a'@$~'b'c'?'bb@%%$?b
38 +f!-\;!RS\(-a= -! -!#=-a-b-'-aa!$$#'a
39 )e\,/"\QR/*, +;;,\;,\@+, ,a,-, \##@-
40 (d/.?~/PQ?^.;)""./"./!).;. .,.;;/@@!,;
41 *c?9'=?OP'%9"(~~9?~9?\(9"9;9.9""?!!\."
42 ^b'8-+'NO-$8~*==8'=8'/*8~8"898~~'\\/9~
43 %a-7,)-MN,#7=^++7-+7-?^7=7~787==-//?8=
44 $ ,6.(,LM.@6+%))6,)6,'%6+6=676++,??'7+
45 #;.59*.KL9!5)$((5.(5.-$5)5+565)).''-6)
46 @"948^9JK8\4(#**49*49,#4(4)454((9--,5(
47 !~837%8IJ7/3*@^^38^38.@3*3(343**8,,.4*
48 \=726$7HI6?2^!%%27%279!2^2*232^^7..93^
49 /+615#6GH5'1%\$$16$168\1%1^121%%69982%
50 ?)504@5FG4-0$/##05#057/0$0%010$$58871$
51 '(4Z3!4EF3,Z#?@@Z4@Z46?Z#Z$Z0Z##47760#
52 -*3Y2\3DE2.Y@'!!Y3!Y35'Y@Y#YZY@@3665Z@
53 ,^2X1/2CD19X!-\\X2\X24-X!X@XYX!!2554Y!
54 .%1W0?1BC08W\,//W1/W13,W\W!WXW\\1443X\
55 9$0VZ'0ABZ7V/.??V0?V02.V/V\VWV//0332W/
56 8#ZUY-ZzAY6U?9''UZ'UZ19U?U/UVU??Z221V?
57 7@YTX,YyzX5T'8--TY-TY08T'T?TUT''Y110U'
58 6!XSW.XxyW4S-7,,SX,SXZ7S-S'STS--X00ZT-
59 5\WRV9WwxV3R,6..RW.RWY6R,R-RSR,,WZZYS,
60 4/VQU8VvwU2Q.599QV9QVX5Q.Q,QRQ..VYYXR.
61 3?UPT7UuvT1P9488PU8PUW4P9P.PQP99UXXWQ9
62 2'TOS6TtuS0O8377OT7OTV3O8O9OPO88TWWVP8
63 1-SNR5SstRZN7266NS6NSU2N7N8NON77SVVUO7
64 0,RMQ4RrsQYM6155MR5MRT1M6M7MNM66RUUTN6
65 Z.QLP3QqrPXL5044LQ4LQS0L5L6LML55QTTSM5
66 Y9PKO2PpqOWK4Z33KP3KPRZK4K5KLK44PSSRL4
67 X8OJN1OopNVJ3Y22JO2JOQYJ3J4JKJ33ORRQK3
68 W7NIM0NnoMUI2X11IN1INPXI2I3IJI22NQQPJ2
69 V6MHLZMmnLTH1W00HM0HMOWH1H2HIH11MPPOI1
70 U5LGKYLlmKSG0VZZGLZGLNVG0G1GHG00LOONH0
71 T4KFJXKklJRFZUYYFKYFKMUFZF0FGFZZKNNMGZ
72 S3JEIWJjkIQEYTXXEJXEJLTEYEZEFEYYJMMLFY
73 R2IDHVIijHPDXSWWDIWDIKSDXDYDEDXXILLKEX
74 Q1HCGUHhiGOCWRVVCHVCHJRCWCXCDCWWHKKJDW
75 P0GBFTGghFNBVQUUBGUBGIQBVBWBCBVVGJJICV
76 OZFAESFfgEMAUPTTAFTAFHPAUAVABAUUFIIHBU
77 NYEzDREefDLzTOSSzESzEGOzTzUzAzTTEHHGAT
78 MXDyCQDdeCKySNRRyDRyDFNySyTyzySSDGGFzS
79 LWCxBPCcdBJxRMQQxCQxCEMxRxSxyxRRCFFEyR
80 KVBwAOBbcAIwQLPPwBPwBDLwQwRwxwQQBEEDxQ
81 JUAvzNAabzHvPKOOvAOvACKvPvQvwvPPADDCwP
82 ITzuyMz ayGuOJNNuzNuzBJuOuPuvuOOzCCBvO
83 HSytxLy; xFtNIMMtyMtyAItNtOtutNNyBBAuN
84 GRxswKx";wEsMHLLsxLsxzHsMsNstsMMxAAztM
85 FQwrvJw~"vDrLGKKrwKrwyGrLrMrsrLLwzzysL
Looking this over, it's pretty obvious that offset 19 yields normal English letters, punctuation, and spacing, and everything else doesn't. (Of course, since we're only looking at every sixth letter, the result isn't readable.) We can repeat this for the other positions in the string
(testall s 0 6)
...
59 SepdaVirouumw eelche e ne?i iibri ier
...
(testall s 1 6)
...
59 ilr,leckwl e y syki,l ye oImttidtcn i
...
By scanning the six sets of outputs, the obvious key set is (59 59 19 9 24 50).
Now we can write a simple function to decrypt the entire string from a list of offsets:
(def decode (s offsets)
(for i 0 (- (len s) 1)
(pr (decodechar (s i) (offsets (mod i (len offsets))))))
(prn))
(decode s '(59 59 19 9 24 50))
Sincerely impressed, cheald. Very nice work. Now, could you let me know that you've successfully cracked this one, and let me give you one more test? Obviously I can make it a little bit harder without changing the algorithm.
The original algorithm uses a string for the key, not integers, so we can map the offsets back to a string key:
(each x '(59 59 19 9 24 50) (pr (m x)))
66sixXnil
Ignoring
nil, the key is "66sixX". Thus, a few minutes with Arc is sufficient to break the cipher and determine the original key.
The reddit thread includes multiple other challenges. One is:
(= s2 "sBC^myM3f5MC6nBF~d?OM*mqt5y@wB3Bvt'm6vy%vIB3x9RNJmJB@y,Bt6rHN4m@FS3nrF8d(It5rpL8e8:t^BpN,e(tw,AuO?m^wB8ApG4C4Ny^GpI(x4NB-Fpy!g^SJ*vEH3q9NB@q+t3M.tB8mIO6g9yx^mpQ8p\\tx@Auf3dhtM-Asy%i\\St6BDA%e(OF4Gut,m!;t3Vvt,i4xI8FpH@x4t23nIE3x-uN3nJt/i5MN3uut!s(tw@AJC!y9tN@mCu?i4zO!mEz3x-CM3pyJ,i^tQ,vsB3m*tM@muu^C4ut1$pS8e^tI/qnt6s)Fx3pHu6o4CNJmEL3b'Nt6nDt5i4wL4pAy7d6St,nDx1d5ww@EtC!k4NI3BJB8v*;t3YuN3q9tL8Cuu*d#Hw8mCI%i4t23xDI+d'NtaN3t5i4wL4pAy7/4vO*mYt5i(t6m59t#i#JF8miL8h8CN3vIt!s(tr\\BIN3t9IJ/rnn3A#Hb*mtI3m(;")
The same technique finds the key length is 9, the offsets are (57 20 20 56 13 16 20 56 4), and the plaintext and key are:
(decode s2 '(57 20 20 56 13 16 20 56 4))
This is basically just a bunch of jibberish text, though certainly able to be read, so that chneukirchen may test out this encryption method. If he succeeds well done! I sincerely congratulate him. If he does not I ask that at least he not continue to make fun of this cipher which is so easy a "7 year old" could crack it, or "it can be cracked by hand" according to others. Let me repeat once more I know it CAN be cracked, but I bet MOST people (reddit is not "most people") won't do it.
(each x '(57 20 20 56 13 16 20 56 4) (pr (m x)))
4tt3mpt3dnil
This shows how Arc can be used as a tool in simple cryptanalysis, and also shows that homegrown cryptography can be very weak. If you're interested in cryptography, I highly recommend that you read
Applied Cryptography
. If it's the history of cryptography that interests you, I recommend
The Codebreakers
.