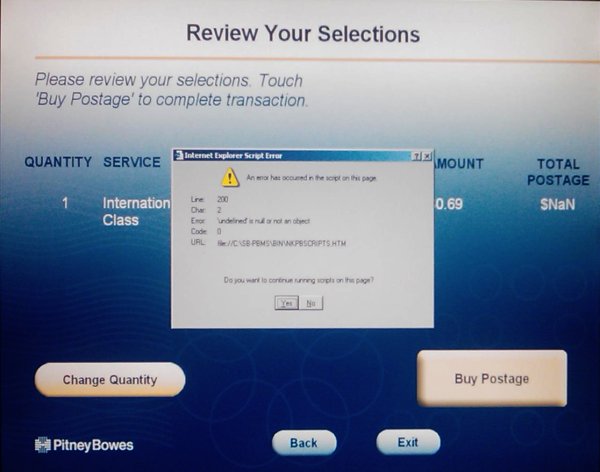
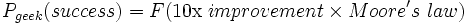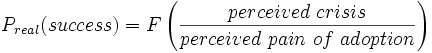- Correlation is not causation: the few readers who don't know this already won't benefit from mentioning it. If there's some specific reason you think a a study is wrong, describe it.
- "If you're not paying for it, you're the product" - That was insightful the first time, but doesn't need to be posted about every free website.
- Explaining a company's actions by "the legal duty to maximize shareholder value" - Since this can be used to explain any action by a company, it explains nothing. Not to mention the validity of the statement is controversial.
- [citation needed] - This isn't Wikipedia, so skip the passive-aggressive comments. If you think something's wrong, explain why.
- Premature optimization - labeling every optimization with this vaguely Freudian phrase doesn't make you the next Knuth. Calling every abstraction a leaky abstraction isn't useful either.
- Dunning-Kruger effect - an overused explanation and criticism.
- Betteridge's law of headlines - this comment doesn't need to appear every time a title ends in a question mark.
- A link to a logical fallacy, such as ad hominem or more pretentiously tu quoque - this isn't a debate team and you don't score points for this.
- "Cue the ...", "FTFY", "This.", "+1", "Sigh", "Meh", and other generic internet comments are just annoying.
- The plural of anecdote is not data
- Cargo cult
- Comments starting with "No." "Wrong." or "False."
- Just use bootstrap / heroku / nodejs / Haskell / Arduino.
- "How [or Why] did this make the front page of HN?" followed by http://ycombinator.com/newsguidelines.html
What comments bother you the most?
Amusing note: when I saw the comments below, I almost started deleting them thinking "These are the stupidest comments I've seen in a long time". Then I realized I'd asked for them :-)
There are three basic types of online participants: "watercooler", "scientific conference", and "debate team". In "watercooler", the participants are having an entertaining conversation and sharing anecdotes. In "scientific conference", the participants are trying to increase knowledge and solve problems. In "debate team", the participants are trying to prove their point is right.
HN was originally largely in the "scientific conference" mode, with very smart people discussing areas in which they were experts. Now HN has much more "watercooler" flavor, with smart people chatting about random things they often know little about. And certain subjects (e.g. economics, Apple, sexism, piracy) bring out the "debate team" commenters. Any of the three types can carry on happily by themself. However, much of the problem comes when the types of conversation mix. The "watercooler" conversations will annoy the "scientific conference" readers, since half of what they say is wrong. Conversely, the "scientific conference" commenters come across as pedantic when they interrupt a fun conversation with facts and corrections. A conversation between "debate team" and one of the other groups obviously goes nowhere.